X min de lecture
Table des matières

Chez Cloud-IAM, nous opérons Keycloak en mode managé. Concrètement, cela signifie que nous exploitons un grand nombre de clusters, sur de nombreuses versions, sous une vraie charge de production. Quand une régression apparaît, on n'a pas le luxe d'ouvrir un ticket et d'attendre. On instrumente, on profile, et on remonte jusqu'à la cause racine. Voici le récit d'une de ces traques.
Nous avons migré le cluster d'un client vers Keycloak 26.6. Trois nœuds, 4 vCPU et 8 Go chacun, l'image officielle, rien d'exotique.
Pendant un temps, tout s'est bien passé. Le CPU suivait le volume de requêtes, comme il se doit. Puis, sans déploiement, sans pic de trafic, sans tâche planifiée, un nœud a bondi à 40 % de CPU, parfaitement stable, et n'en a plus bougé.
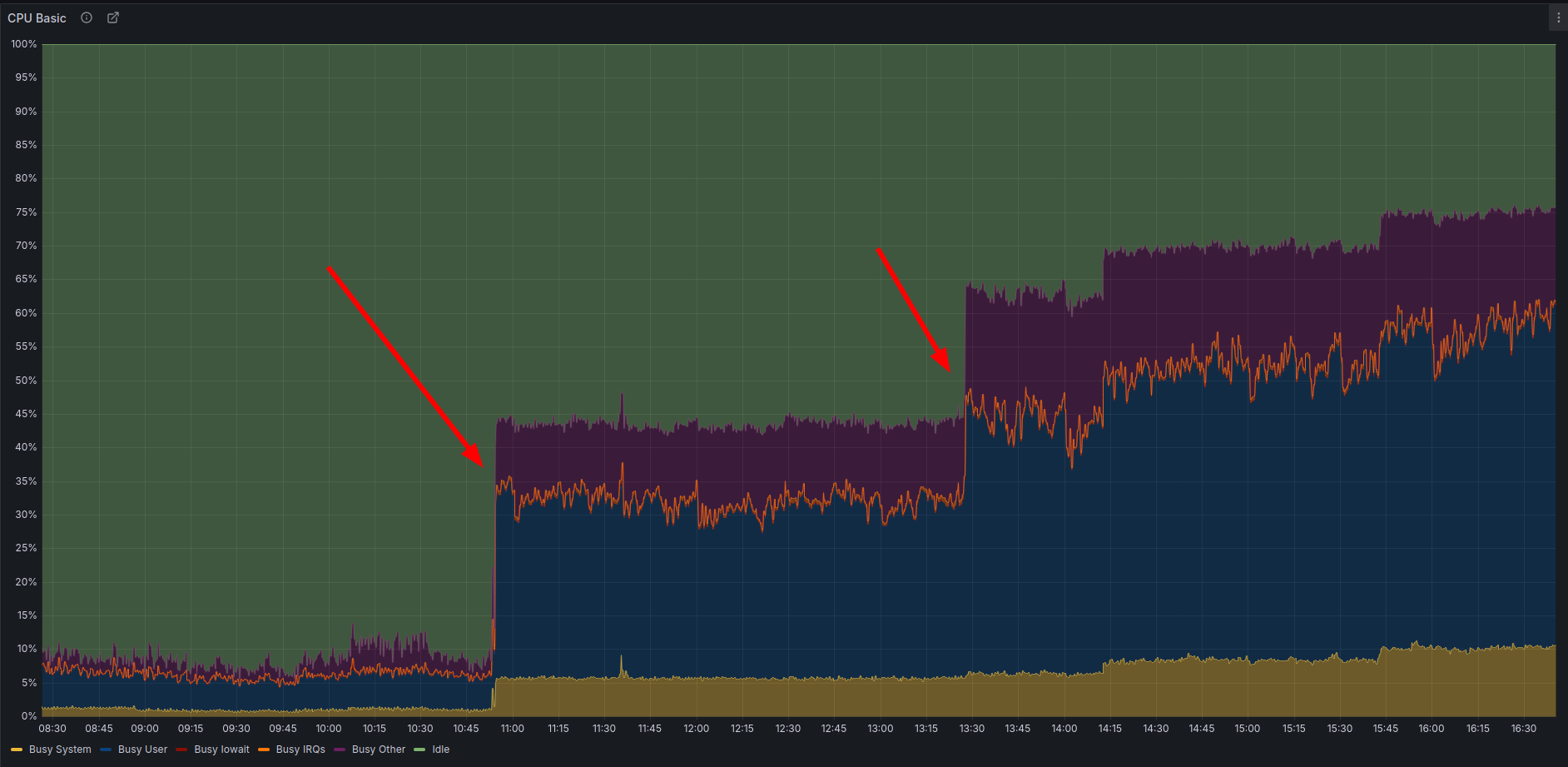
CPU Basic. Des paliers nets, aucun retour en arrière, une montée progressive sur la journée.
Plusieurs éléments rendaient le cas intéressant plutôt que banal :
Une consommation CPU indépendante du trafic, qui survit au drainage et ne se réinitialise qu'au redémarrage, ce n'est pas un problème de capacité. Quelque chose tournait en boucle à l'intérieur du process.
Le cluster fait tourner quelques-uns de nos propres SPI. La première hypothèse honnête était donc : « ça vient de nous ». On y a consacré un vrai temps. On a récupéré des thread dumps et des profils de méthodes pour chercher nos propres packages sur le chemin chaud.
Ils n'y étaient pas. Ni dans les stack traces, ni dans le profiling de méthodes, ni dans le profil d'allocation. Les preuves pointaient systématiquement vers le runtime lui-même, pas vers ce qui était posé par-dessus. On a donc cessé de vouloir faire de notre code le coupable, et on a suivi les données.
Cela mérite d'être dit clairement, car c'est l'étape que tout le monde saute : la discipline consiste à abandonner la théorie qui arrange dès l'instant où le profiler la contredit.
Nous avons attaché JFR à un nœud affecté et l'avons laissé enregistrer pendant l'un des paliers CPU.
Le taux de changements de contexte des threads a livré le premier indice. Au repos, il tournait autour de 3 kHz. Pendant l'épisode, il grimpait à environ 40 kHz. Ce n'est pas un thread qui travaille. C'est un thread qui se met en pause puis se fait réveiller, encore et encore, aussi vite que l'ordonnanceur le permet.
Le profil d'allocation l'a confirmé. Le plus gros allocateur du tas mémoire était org.jboss.threads.EnhancedQueueExecutor$PoolThreadNode, avec 26,9 Gio d'allocations cumulées en quelques minutes, bien au-delà de la moindre charge utile de requête. La machinerie même du pool de threads de l'executor brassait de la mémoire. Les threads étaient occupés à être occupés, pas à servir des requêtes.
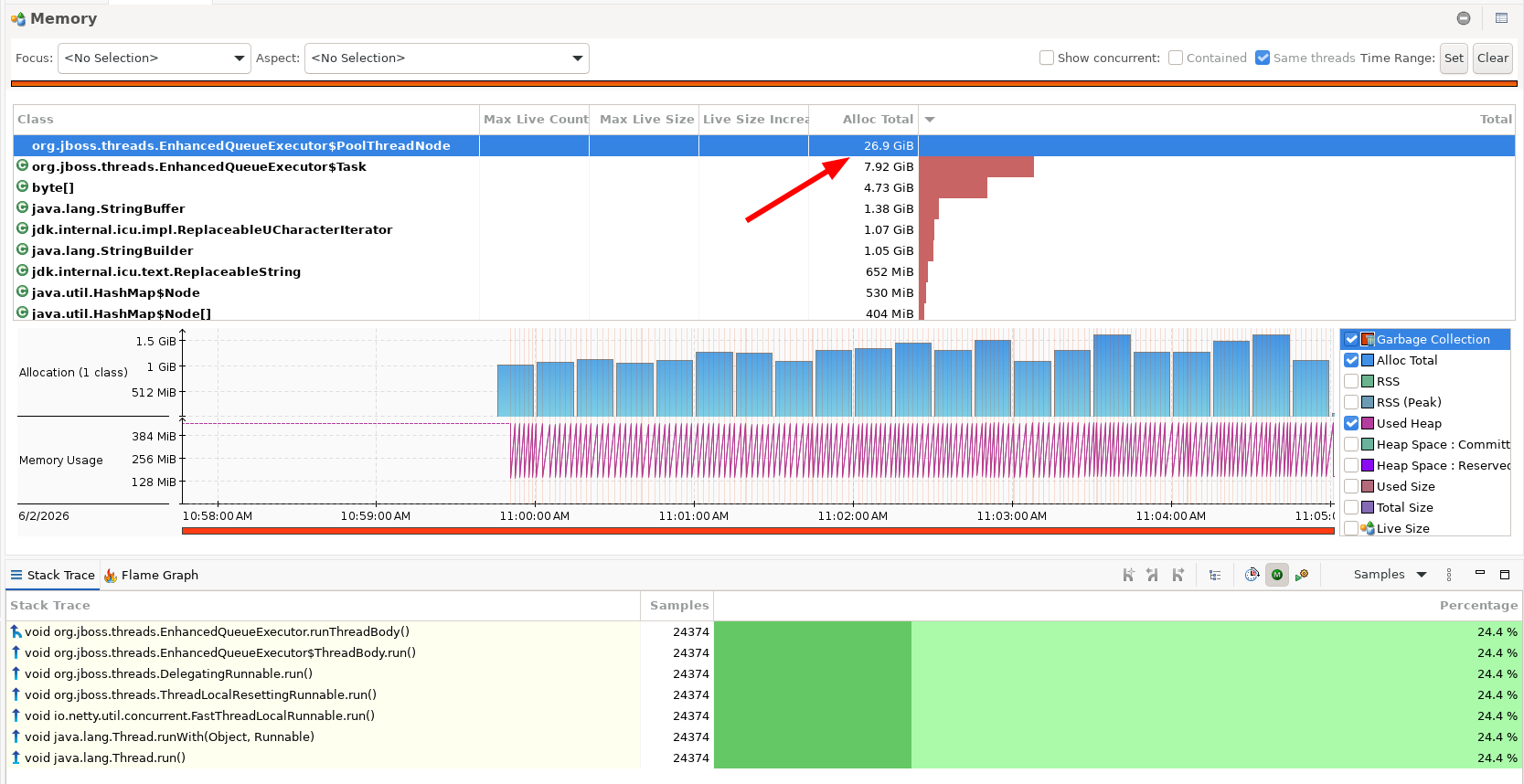
Vue mémoire JFR. PoolThreadNode domine l'Alloc Total avec 26,9 Gio en quelques minutes.
Le profil de méthodes a permis de cerner le coupable. Près de la moitié des échantillons se trouvaient dans EnhancedQueueExecutor$PoolThreadNode.park(), associés à System.unparkVirtualThread(). Park, unpark, park, unpark, dans une boucle serrée. Le CPU était entièrement consommé par l'ordonnancement : des threads qui s'endorment et qu'on réveille aussitôt.
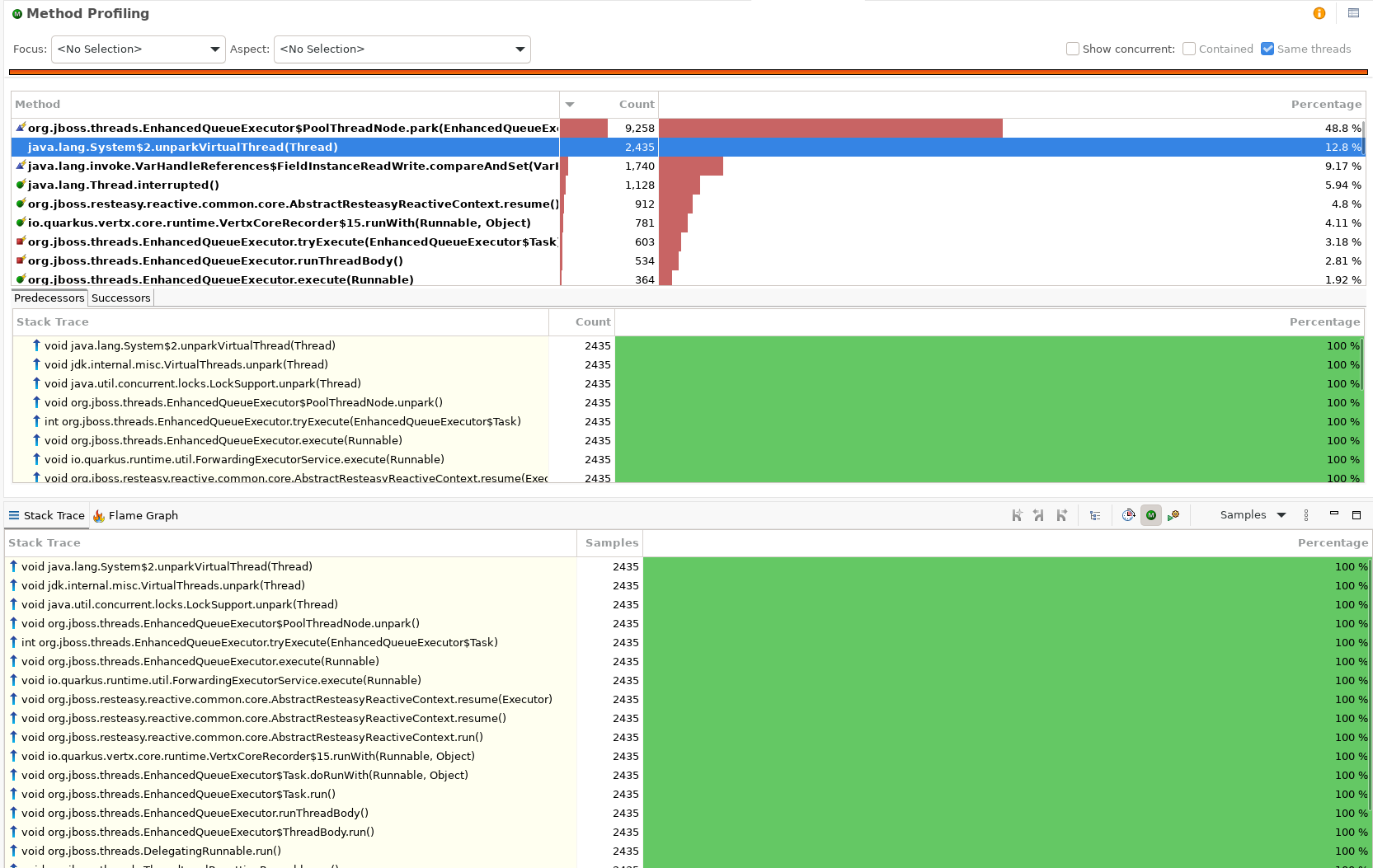
Profiling de méthodes JFR. park() et unparkVirtualThread() dominent les échantillons.
Nous avions donc un mécanisme clair pour la surconsommation : une boucle park/unpark serrée sur l'executor. La question devenait : qu'est-ce qui ne cesse de la réamorcer ?
Si du travail est re-soumis indéfiniment, c'est que quelque chose est encore vivant alors qu'il ne devrait plus l'être. Nous avons pris un heap dump et cherché des objets de requête qui avaient survécu à leur propre requête.
Ils étaient bien là. Avec Eclipse MAT, nous avons trouvé des instances vivantes de QuarkusResteasyReactiveRequestContext, l'objet par requête que Quarkus RESTEasy Reactive utilise pour faire avancer une requête dans son pipeline. Nous avons remonté le plus court chemin vers la racine GC pour l'une d'elles. Certaines restent rattachées à une KeycloakSession, mais elles sont marquées comme terminées : on peut les écarter pour cette enquête.
Les cas intéressants sont liés, via la mécanique interne de Vert.x, à un contexte de requête encore vivant. Ce n'étaient pas des déchets en attente d'un passage du GC. Ils étaient atteignables, ce qui signifie que le runtime les considérait toujours en cours de traitement.
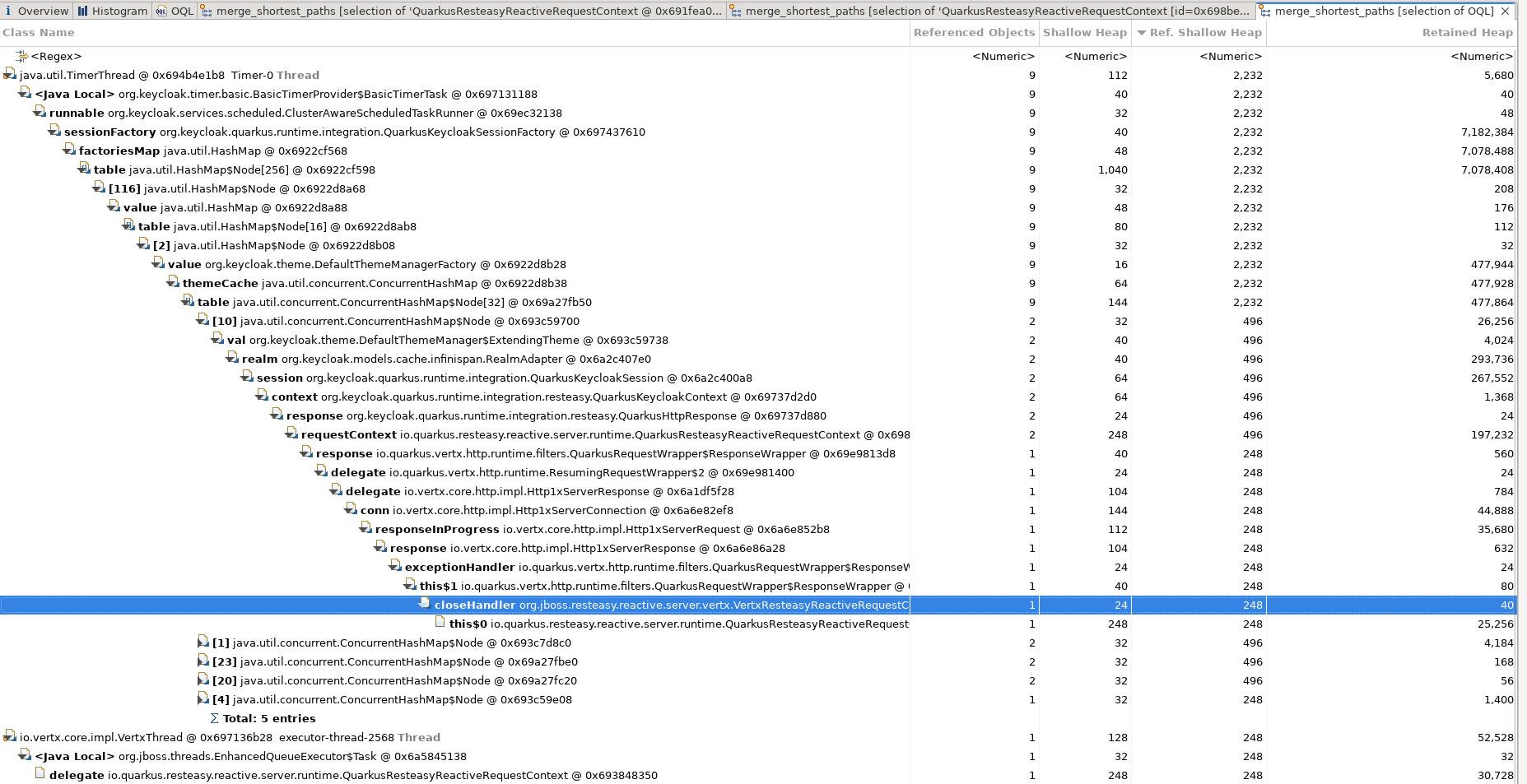
Chemin vers la racine GC. Un contexte de requête vivant, retenu par la chaîne de réponse Vert.x.
Des requêtes d'apparence terminée, toujours épinglées en mémoire, toujours considérées comme actives. Voilà le carburant. Il nous fallait maintenant l'étincelle.
Dans Quarkus RESTEasy Reactive, une requête est traitée en appliquant une chaîne de handlers les uns après les autres. Un curseur position indique où en est la requête dans la chaîne. Après l'exécution de chaque handler, la position avance et le handler suivant est invoqué. La requête est terminée quand position == handlers.length, c'est-à-dire quand le curseur atteint la fin de la chaîne.
Nous avons écrit une requête OQL sur le heap dump pour inspecter directement ces contextes vivants, en comparant la position de chacun à la longueur de sa chaîne de handlers.
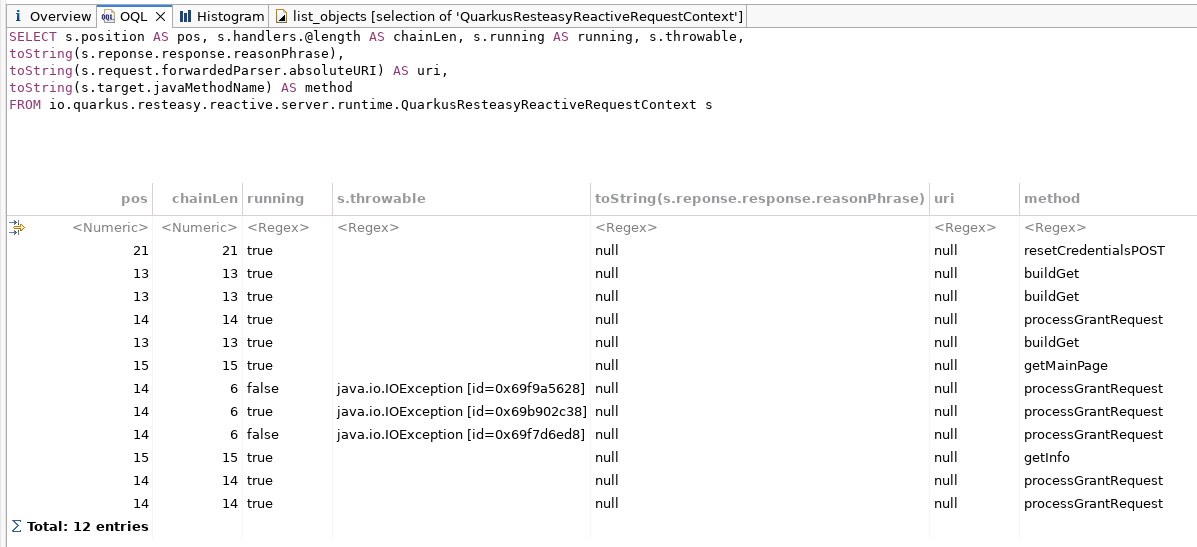
OQL sur les contextes vivants. position (pos) se situe bien au-delà de la longueur de la chaîne de handlers (chainLen).
Le résultat résumait tout le bug en un seul tableau. Plusieurs contextes affichaient position = 14 alors que leur chaîne de handlers n'en comptait que 6. Le curseur pointait vers le handler numéro 14 dans une liste qui n'en contenait que 6. Ils étaient marqués comme « en cours d'exécution », certains portaient une IOException, et il ne restait tout simplement aucun handler vers lequel avancer.
Un curseur au-delà de la fin de son propre tableau, ce n'est pas un état que le chemin nominal peut produire. Quelque chose avait déplacé le curseur indépendamment de la chaîne qu'il était censé parcourir.
Voici ce qui se passe, avec nos remerciements à Steven Hawkins et Peter Zaoral, qui ont traqué le problème jusque dans le code. Il faut que deux choses surviennent quasiment au même instant.
D'abord, une exception pendant la lecture de la requête. Une connexion client se coupe en pleine lecture, le corps de la requête échoue au parsing, une IOException est levée. RESTEasy Reactive gère cela en abandonnant la chaîne de handlers normale et en basculant la requête vers un jeu dédié de handlers d'erreur. Cette chaîne d'erreur est plus courte. Dans les cas observés, 6 handlers au lieu de la liste initiale, plus longue.
Ensuite, au même instant, le runtime appelle discardRemaining(). Son rôle est exactement celui que son nom indique : garantir qu'aucun handler supplémentaire ne s'exécute et libérer les ressources liées à la requête. Pour cela, il propulse le curseur directement à la fin :
/**
* This method ensures that no more handlers will run and that all the resources tied
* to the request are closed
*/
private void discardRemaining() {
setPosition(getHandlers().length);
close();
}
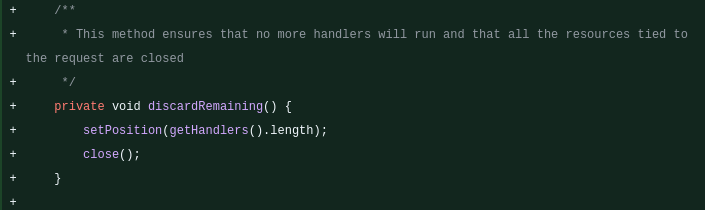
La méthode telle qu'elle apparaît dans le diff du code source.
Prises isolément, les deux opérations sont correctes. Le bug naît de leur chevauchement.
discardRemaining() lit getHandlers().length et fixe position à cette valeur. Mais il lit la longueur de la liste de handlers en vigueur au moment de son exécution, alors que le chemin d'exception est justement en train de remplacer cette liste par la chaîne d'erreur, plus courte. Le curseur se retrouve initialisé à partir de la longueur de l'ancienne liste, la plus longue, puis pointe dans la nouvelle liste, plus courte. Position 14 contre une chaîne de 6.
À partir de là, la requête est coincée. La condition de terminaison est position == handlers.length. Avec une position strictement supérieure à handlers.length, cette égalité ne peut jamais être vraie. La requête ne peut jamais être marquée comme terminée.
Et c'est là que la boucle observée dans le profiler se referme. L'executor reprend la requête pour la faire avancer. Il ne trouve aucun handler à la position courante, donc il ressort presque instantanément sans rien avoir fait. Mais le test de terminaison échoue toujours : la requête reste active et est re-planifiée. Reprise, rien trouvé, sortie, remise en file. Indéfiniment.
Voilà les 40 % plats. Une requête coincée, c'est un thread du pool enfermé dans une boucle park/unpark infinie. Chaque nouvelle connexion rompue qui perd la même course coince une autre requête, épingle un autre thread, et ajoute son propre +20 %. Un redémarrage purge d'un coup tous les contextes coincés, ce qui explique exactement pourquoi le redémarrage corrigeait le problème, et pourquoi il revenait toujours.
Il faut qu'une requête échoue pendant sa lecture, précisément avec une exception qui déclenche le basculement vers les handlers d'erreur, au moment exact où discardRemaining() s'exécute sur cette requête. Sur un cluster calme, ces deux événements peuvent ne jamais coïncider. Sur un cluster chargé, avec de vrais clients qui coupent leurs connexions, ils finissent par coïncider, sur chaque nœud, sans fréquence particulière. C'est précisément le comportement que nous avons observé.
C'est une vraie race condition : elle ne se plie pas à des étapes de reproduction. C'est ce qui rend ici un heap dump et un profil d'allocation bien plus utiles que des heures passées à scruter les logs.
Nous pensons que c'est une bonne illustration de ce qu'exige réellement l'exploitation de Keycloak managé à grande échelle, et de ce que nous y apportons.
Nous n'avons pas deviné. Nous avons profilé le CPU, les changements de contexte, l'allocation et le tas mémoire, en laissant chaque couche de preuves orienter la suivante. Nous avons accepté de réfuter notre propre première hypothèse dès que les données nous ont contredits. Et nous ne nous sommes pas arrêtés à « c'est un problème interne de Quarkus » : nous sommes descendus jusqu'à la méthode exacte, le champ exact, et l'ordre précis des deux opérations qui doivent se produire pour que la panne survienne.
C'est le niveau auquel nous opérons, sur chaque cluster que nous exploitons. Quand une régression arrive en amont, nos clients ne la subissent pas comme une panne mystérieuse. Nous la trouvons, nous l'expliquons, et nous portons le correctif.
Si vous exploitez Keycloak et préférez une équipe qui débugge le runtime plutôt qu'une qui le redémarre, c'est exactement à cela que sert Cloud-IAM.
Cloud-IAM exploite Keycloak managé en production. Cette investigation a été menée sur un cluster 26.6 en production.
L'histoire complète, y compris la discussion et le correctif en amont, est suivie dans keycloak/keycloak#49635.



